

在AI快速渗透语音领域的今天,一款真正兼顾“高质量输出”和“可自定义部署”的中文TTS工具,并不常见。而最近,一款由 OpenMOSS 社区主导开发的开源项目 MOSS-TTSD,正在引起语音合成领域的广泛关注。

如果你正在寻找一个可训练、可拓展、效果出众的中文语音合成系统,无论是应用落地还是科研探索,MOSS-TTSD 都值得你认真了解。
一、从文本到人声,只需几毫秒
与传统 TTS 系统冗长的处理流程不同,MOSS-TTSD 专注“快”和“真”两件事。
基于当前主流的神经网络结构(如 Tacotron、FastSpeech、HiFi-GAN 等),能够生成自然、连贯、接近人类发音的语音。更重要的是,在边缘设备上也能实现低延迟响应,为实时播报、智能交互等场景提供了极大的便利。
二、五大技术特性,重构语音合成体验
多语言支持,以中文为核心拓展至多语系
项目以中文普通话为基础,但架构本身已支持英文及其他语种扩展。语调、语速、语气变化高度可控,覆盖从新闻播报到客服语音的多样场景。
高保真音频输出,听感更接近人声
支持高达 44kHz 的音频采样率输出,并集成多种神经声码器,如 WaveGlow 与 HiFi-GAN,生成的语音自然度足以应用于播客、有声书等高质量内容创作。
语音参数可控,适应不同听众需求
你可以任意调整语速、音调、音量、停顿等参数,甚至定制风格化语音(童声、年长者音色、正式或口语化语调等),满足个性化内容生成需求。
部署灵活,支持实时与离线生成
支持单条语音快速生成,也能进行批量处理,尤其适合大规模数据生产或线上实时服务场景。整体模型经过轻量化优化,10G显存即可平稳运行。
模块化设计,便于替换与训练
系统分为文本处理、声学模型与声码器三个独立模块,任何一部分都可以按需替换或微调。配套脚本可快速接入本地语音数据进行训练,实现完全自定义语音合成系统。
三、MOSS-TTSD 的底层结构全解
1. 文本前端模块
对输入文本进行清洗、分词、拼音注音与韵律预测等,建立语音合成的结构基础。
2. 声学模型部分
将语音特征转化为中间频谱表示(如梅尔频谱图),兼容 FastSpeech2、Tacotron2 等主流模型。
3. 神经声码器
用于生成最终语音波形,支持 WaveGlow、Parallel WaveGAN、HiFi-GAN 等高效模型,适合多种计算资源环境。
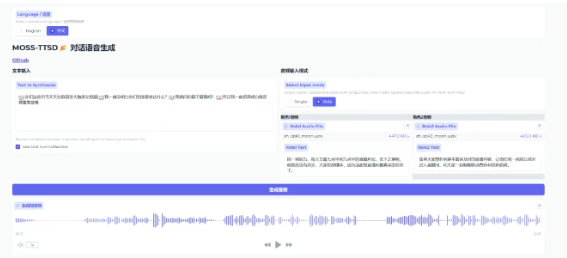
四、支持场景全面覆盖
MOSS-TTSD 的开放性与专业性,使其适用于多个真实业务场景:
智能客服:结合问答系统生成实时语音回应,优化用户交互体验
听书/有声读物:实现任意文本内容的语音输出,提升内容可达性
在线教育:用于语文识字、英语口语纠音、教学音频生成等
视障辅助:为盲人用户提供更精准、真实的语音播报服务
自动语音广告:节省配音成本,高效完成语音广告批量生成
五、开发者友好,部署无门槛
该项目面向 NVIDIA 显卡优化,10G 显存即可运行全部模块。无需修改代码,开箱即用,官方文档详细提供了训练流程、模型结构说明及配置范例:
支持 CUDA 自动检测
保持原版模型配置与架构完整
已适配显卡 50 系列以上
无需联网,完全本地部署
如果你已有一定深度学习经验,还可以通过提供的训练脚本,使用自己的语音样本进行微调,实现独属的语音合成模型。







暂无评论内容